크롤링 초보자 기본 가이드, 초급자 원리 파악, 추천 사이트 6가지, 크롤링(Crawling)은 웹페이지에서 데이터를 자동으로 수집하는 기술로, 프로그램이 웹사이트를 탐색하며 필요한 정보를 체계적으로 가져옵니다. 이 기술은 마케팅, 연구, 트렌드 분석, 상품 모니터링 등 다양한 분야에서 활용되며, 데이터를 일일이 복사-붙여넣기 할 필요 없이 시간과 비용을 절감해 줍니다. 특히 대량의 데이터를 지속적으로 추적해야 하는 경우 자동화된 크롤러가 필수적입니다.

목차
💡 1. 웹 크롤링의 기본 원리
웹 크롤링은 URL 탐색, HTML 파싱, 데이터 정제의 단계로 구성됩니다. 이 프로세스는 필요한 정보를 빠르고 정확하게 수집하는 데 중점을 둡니다.
1️⃣ URL 탐색과 데이터 수집
크롤러는 지정된 시드 URL(seed URL)에서 시작해, 페이지 내의 링크를 따라 이동하며 내부 링크와 외부 링크를 통해 여러 페이지를 탐색합니다. 이 과정에서 목표 데이터가 포함된 페이지를 자동으로 찾아가며 수집합니다.
2️⃣ HTML 파싱과 데이터 추출
웹페이지의 데이터를 추출하기 위해 HTML 소스 코드를 분석합니다. 크롤러는 태그(tag), 클래스(class), ID와 같은 요소를 식별해 필요한 정보만 정확히 가져옵니다. 예를 들어, 상품명, 가격, 기사 제목 등을 특정 HTML 태그로부터 추출합니다.
3️⃣ 데이터 저장 및 정제
수집된 데이터는 CSV, JSON, 데이터베이스 등 다양한 형식으로 저장되며, 정제 과정에서 중복 제거와 오류 수정이 이루어집니다. 정제된 데이터는 데이터 분석과 머신러닝 모델에 활용하기 적합한 상태로 변환됩니다.
✅ 크롤링 도구 추천: 데이터 수집을 위한 5가지 최적의 사이트 🚀
🛠️ 2. 초보자를 위한 추천 도구 6가지
1️⃣ Octoparse
Octoparse는 코딩 없이 데이터를 수집할 수 있는 GUI 기반의 도구로, 비개발자도 쉽게 사용할 수 있습니다. 클릭과 드래그앤드롭만으로 데이터를 수집하며, 클라우드 기능을 통해 대규모 데이터 수집을 자동화할 수 있습니다. 동적 웹사이트도 지원하여 마케팅 분석, 상품 모니터링 등에 유용합니다.

주요 특징:
- 코딩 불필요: 드래그앤드롭 방식으로 설정 가능
- 클라우드 크롤링 지원: 대량 데이터를 서버 부담 없이 수집
- 동적 웹사이트 지원: JavaScript 기반 사이트에서도 크롤링 가능
- 데이터 저장: CSV, Excel, API 등으로 결과 출력
적용 사례:
- 이커머스 가격 모니터링: 쇼핑몰의 가격 및 재고 추적
- 고객 리뷰 분석: 사용자 피드백 데이터 수집 및 분석
- 시장 트렌드 파악: 특정 주제의 주간 및 월간 트렌드 모니터링
장점:
- 비개발자 친화적: 복잡한 설정 없이 크롤링 가능
- 반복 작업 자동화: 일정에 따라 주기적인 데이터 수집
- 클라우드 백업: 수집 데이터를 안전하게 저장
단점:
- 무료 플랜 제한: 고급 기능은 유료 플랜에서만 제공
- 복잡한 크롤링에 한계: 커스터마이징에 제약이 있음
Octoparse는 코딩 지식이 없는 사용자나 초보자에게 적합하며, 자동화된 대량 데이터 수집이 필요한 비즈니스 분석에 유용합니다.
2️⃣ Parsehub
Parsehub는 JavaScript와 AJAX 기반의 동적 웹사이트에서도 데이터를 수집할 수 있는 강력한 도구입니다. 복잡한 사이트에서 여러 페이지를 탐색하며 데이터를 추출할 수 있으며, API 기능을 통해 실시간 데이터 연동이 가능합니다. 다양한 조건과 필터를 적용해 정교한 크롤링 작업을 수행합니다.
주요 특징:
- 동적 콘텐츠 지원: JavaScript와 AJAX 기반 웹사이트 크롤링 가능
- 멀티 페이지 탐색: 여러 페이지를 자동으로 탐색하며 데이터 수집
- API 연동 제공: 실시간으로 수집한 데이터를 외부 애플리케이션과 연동
- 사용자 인터페이스: 비개발자도 사용할 수 있는 간편한 GUI 제공
적용 사례:
- 뉴스 수집: 특정 키워드와 관련된 최신 뉴스 기사 자동 수집
- 상품 모니터링: 쇼핑몰의 상품 가격 및 리뷰 추적
- 연구 데이터 수집: 웹 자료를 통한 학술 연구 데이터 확보
장점:
- 다양한 웹사이트 지원: 복잡한 동적 콘텐츠도 문제없이 처리
- 무료 플랜 제공: 소규모 프로젝트에 유용한 무료 옵션
- 사용 편의성: 비개발자도 쉽게 크롤링 설정 가능
단점:
- 제한된 속도: 무료 플랜에서는 크롤링 속도에 제약
- 대규모 데이터 수집에는 한계: 클라우드 기능이 제한될 수 있음
Parsehub는 비개발자와 초보자가 동적 웹사이트에서 데이터를 수집하는 데 유용하며, API 연동으로 실시간 데이터 분석이 필요한 프로젝트에 적합합니다.
3️⃣ Scrapinghub (Zyte)
Scrapinghub (Zyte)는 클라우드 기반의 고성능 크롤링 플랫폼입니다. API와 플러그인을 활용해 복잡한 웹사이트에서도 대규모 데이터를 안정적으로 수집할 수 있으며, IP 회전 기능을 통해 서버 차단을 방지합니다. 대기업과 연구소에서 정기적으로 데이터를 모니터링하는 데 자주 사용됩니다.

주요 특징:
- 클라우드 기반 크롤링: 서버 부담 없이 안정적인 대규모 데이터 수집
- IP 회전 기능: IP 차단 없이 여러 사이트에서 안전하게 크롤링
- API 제공: 수집된 데이터를 실시간으로 분석 및 처리
- 부하 조절 기능: 서버 상태에 맞춰 수집 속도 조절 가능
적용 사례:
- 이커머스 분석: 상품 리뷰와 가격 정보 수집 및 비교
- 경쟁사 모니터링: 경쟁사 웹사이트의 업데이트 추적
- 시장 트렌드 조사: 업계 동향 파악 및 신제품 모니터링
장점:
- 대규모 데이터 수집 최적화: 클라우드 기반으로 성능 극대화
- IP 차단 방지: 회전 프록시를 통한 안전한 크롤링
- 다양한 데이터 형식 지원: CSV, JSON, 데이터베이스 등으로 저장 가능
단점:
- 비용 부담: 고급 기능 사용 시 비용이 발생
- 초보자에겐 어려움: 개발 지식이 필요한 설정 과정
Scrapinghub은 대규모 데이터 분석과 정기적인 모니터링이 필요한 기업에 적합하며, 클라우드 기반으로 안정적인 수집 환경을 제공합니다.
4️⃣ ScrapeStorm
ScrapeStorm은 AI 기반 데이터 수집 도구로, 사용자의 설정 의도를 학습해 자동으로 데이터를 추출합니다. 이미지와 텍스트를 동시에 수집할 수 있으며, 복잡한 설정 없이도 비정형 데이터를 쉽게 정제합니다. 특히 소셜 미디어 데이터 분석과 리뷰 수집에 강점이 있습니다.

주요 특징:
- AI 기반 자동화: 사용자의 의도를 학습해 설정 간소화
- 이미지와 텍스트 동시 수집: 다양한 데이터 형식을 지원
- 데이터 정제 기능: 수집한 데이터를 자동으로 정리
- 클라우드 지원: 대규모 데이터도 안정적으로 처리
적용 사례:
- 리뷰 분석: 쇼핑몰의 고객 리뷰를 수집해 분석
- 소셜 미디어 모니터링: 해시태그와 사용자 반응 분석
- 마케팅 캠페인 성과 측정: 온라인 캠페인 성과 추적
장점:
- 초보자 친화적: 복잡한 설정 없이 사용 가능
- AI 활용: 효율적인 데이터 수집과 정제
- 다양한 포맷 지원: 텍스트와 이미지 데이터 모두 수집 가능
단점:
- 무료 버전 제한: 고급 기능 사용 시 유료 플랜 필요
- 복잡한 대규모 프로젝트에는 한계: 일부 고급 기능의 제약
ScrapeStorm은 초보자와 비개발자에게 적합하며, 소셜 미디어와 리뷰 데이터 수집이 필요한 마케팅 분석 프로젝트에 유용합니다.
5️⃣ BeautifulSoup (Python Library)
BeautifulSoup은 Python 기반의 HTML 파싱 라이브러리로, 간단한 웹 크롤링과 데이터 추출에 적합합니다. 복잡한 HTML 구조도 쉽게 탐색하며, 다른 Python 라이브러리와 함께 사용하면 강력한 기능을 발휘합니다.

주요 특징:
- 오픈소스 라이브러리: 무료로 사용 가능
- HTML/XML 파싱 최적화: 복잡한 웹 구조에서도 데이터 추출 용이
- 유연한 스크립트 작성: 맞춤형 크롤러 제작 가능
- 다양한 데이터 형식 지원: CSV, JSON 등으로 데이터 저장 가능
적용 사례:
- 연구 데이터 수집: 학술 프로젝트를 위한 웹 자료 추출
- 웹 아카이브 구축: 특정 웹사이트의 콘텐츠 보존
- 데이터 시각화: 수집한 데이터를 그래프로 변환
장점:
- 무료로 사용 가능: 오픈소스로 제공
- 유연한 커스터마이징: 다양한 요구에 맞게 크롤러 개발 가능
- 다양한 라이브러리와 호환: Pandas 등과 함께 사용 가능
단점:
- 대규모 프로젝트에는 부적합: 간단한 작업에 주로 사용
- 프로그래밍 지식 필요: Python에 대한 이해가 필요
BeautifulSoup은 소규모 데이터 수집과 연구 프로젝트에 유용하며, 간단한 HTML 파싱 작업에 최적화된 도구입니다.
6️⃣ Scrapy
Python으로 개발된 오픈소스 크롤링 프레임워크입니다. 비동기 방식을 통해 빠른 속도로 대규모 데이터를 수집하며, 확장성과 속도가 뛰어납니다.

주요 특징:
- 비동기 처리: 동시에 여러 페이지 크롤링 가능
- 확장성: 플러그인과 미들웨어를 통해 기능 확장 가능
- 다양한 저장 형식 지원: JSON, CSV 등 원하는 형태로 데이터 저장
적용 사례:
- 경쟁사 사이트 모니터링: 가격 변동과 신제품 출시 파악
- 뉴스 수집: 실시간 뉴스 기사 모니터링
- 이커머스 분석: 대형 쇼핑몰의 상품 정보와 리뷰 데이터 수집
장점:
- 빠른 크롤링 속도: 비동기 방식으로 최적화
- 강력한 커스터마이징: 파이썬 코드를 활용한 맞춤형 크롤러 제작 가능
- 오픈소스 커뮤니티 지원: 풍부한 자료와 문제 해결 도움
단점:
- 초보자에게는 학습 곡선이 높음: 파이썬과 Scrapy 사용법을 익혀야 함
- 복잡한 설정 필요: 간단한 크롤링에는 과할 수 있음
🚨 3. 크롤링 시 유의해야 할 점
1️⃣ robots.txt 준수
웹사이트마다 크롤러의 접근을 제어하는 robots.txt 파일이 있습니다. 이 규칙을 준수하지 않으면 서버에 부하를 주거나 법적 문제가 발생할 수 있습니다.
2️⃣ 저작권 및 데이터 사용 규정 준수
수집한 데이터를 활용할 때는 저작권과 사용 규정을 철저히 확인해야 합니다. 출처를 명확히 밝히고, 데이터를 정당한 용도로 사용해야 합니다.
3️⃣ 트래픽 조절
서버에 과도한 부하를 주지 않도록 크롤링 속도와 요청 간격을 조절해야 합니다. 트래픽 관리를 소홀히 하면 IP 차단 등의 문제가 발생할 수 있습니다.


🎯 4. 크롤링 단계별 예제
(Scrapy 사용) 아래는 Scrapy를 활용해 간단한 웹사이트에서 데이터를 수집하는 Python 코드 예제입니다. 이 코드는 Scrapy 프로젝트를 생성하고, 특정 웹페이지에서 제목 데이터를 추출하는 과정을 보여줍니다.
1️⃣ Scrapy 프로젝트 생성
터미널에서 다음 명령어를 실행합니다.

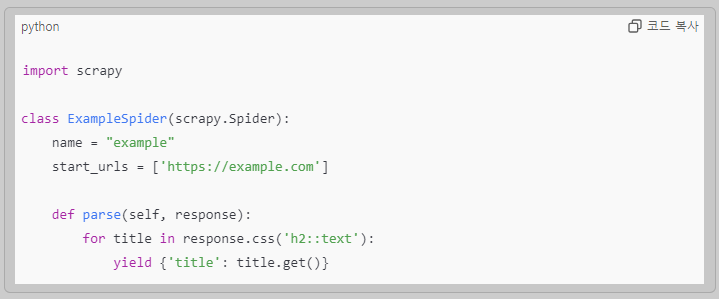
2️⃣ 크롤러 작성 (example_spider.py)
아래와 같이 스파이더 코드를 작성합니다.
3️⃣ 크롤러 실행
아래 명령어를 사용해 크롤러를 실행합니다.

이 코드는 h2 태그에 있는 제목 데이터를 추출해 output.json 파일에 저장합니다.
❓ 5. 자주 묻는 질문 (FAQ)
1. Scrapy와 BeautifulSoup의 차이점은 무엇인가요?
Scrapy는 대규모 웹 크롤링과 비동기 처리에 최적화된 프레임워크입니다. 반면, BeautifulSoup은 소규모 프로젝트나 간단한 HTML 파싱에 적합한 라이브러리입니다.
2. Scrapy는 초보자가 사용하기 어렵나요?
Scrapy는 강력한 기능을 제공하지만, 파이썬에 대한 기본 지식이 필요합니다. 초보자라면 처음에 BeautifulSoup을 사용한 후 Scrapy로 넘어가는 것을 추천합니다.
3. 크롤링 작업이 법적으로 문제가 될 수 있나요?
웹사이트의 robots.txt 규정과 저작권 규정을 준수해야 하며, 상업적 용도로 사용할 경우 사이트의 허가가 필요할 수 있습니다.


✅ Scrapy를 활용한 대규모 데이터 수집 Scrapy는 확장성과 속도가 중요한 대규모 프로젝트에 최적화된 강력한 도구입니다. 비동기 처리를 통해 빠른 속도로 데이터를 수집할 수 있으며, 플러그인과 미들웨어로 다양한 기능을 확장할 수 있습니다.
웹 크롤링을 통해 얻은 데이터를 활용하면 마케팅 전략 수립, 경쟁사 분석, 연구 프로젝트 등에서 유의미한 인사이트를 도출할 수 있습니다.
✅ 크롤링 도구 추천: 데이터 수집을 위한 5가지 최적의 사이트 🚀
크롤링 도구 추천: 데이터 수집을 위한 5가지 최적의 사이트 🚀
크롤링 도구 추천: 데이터 수집을 위한 5가지 최적의 사이트 🚀 , 데이터 수집을 위한 도구 선택의 중요성 데이터는 현대 비즈니스와 학술 연구의 핵심 자원입니다. 기업은 데이터에 기반한 전
richinsighthub.com
🔖 관련 태그
크롤링, 데이터수집, 웹스크래핑, Octoparse, Parsehub, Scrapy, BeautifulSoup, Scrapinghub, Zyte, ScrapeStorm, Diffbot, AI크롤러, 웹크롤링, HTML파싱, Python크롤링, 이커머스분석, 시장조사, 트렌드분석, 경쟁사모니터링, 소셜미디어분석, 상품모니터링, 리뷰분석, 가격추적, 자동화도구, 클라우드크롤링, 비동기처리, API연동, 뉴스수집, 데이터정제, 비정형데이터, JSON저장, CSV저장, 드래그앤드롭, 동적콘텐츠수집, 멀티페이지탐색, robots.txt준수, 서버부하관리, IP회전, 클라우드저장, 데이터시각화, 머신러닝데이터, 마케팅전략, 연구데이터수집, 웹아카이브구축, 경쟁력강화, 무료크롤러, 학술연구, 트래픽관리, 고객피드백분석, 오픈소스크롤러, 파이썬라이브러리, 기업정보모니터링
'IT' 카테고리의 다른 글
| 업비트 도지코인 시세 전망 최고가 (0) | 2024.11.16 |
|---|---|
| 내향적인 HSP(초민감자) 성향에 적합한 직업 추천 (0) | 2024.11.15 |
| 초민감자(HSP) 테스트로 알아보는 나의 민감성 자가 진단 방법과 관리법 (0) | 2024.11.15 |
| HSP 테스트 방법과 절차, 고감성 자가 진단[stress] (0) | 2024.11.15 |
| 크롤링 도구 추천: 데이터 수집을 위한 5가지 최적의 사이트 🚀 (0) | 2024.10.22 |



